Damped Oscillator - CDE¶
Inference without torch dependency:
DMN
MAF
![]()
[1]:
import pickle
import corner
import numpy as np
from vbi import BoxUniform
import autograd.numpy as anp
import matplotlib.pyplot as plt
from multiprocessing import Pool
from vbi.cde import MDNEstimator, MAFEstimator
from sklearn.preprocessing import StandardScaler
from vbi.models.numba.damp_oscillator import DO
from vbi.utils import posterior_shrinkage_numpy, posterior_zscore_numpy
# switch to C++ implementation
# from vbi.models.cpp.damp_oscillator import DO
[2]:
from vbi import report_cfg
from vbi import extract_features
from vbi import get_features_by_domain, get_features_by_given_names
[3]:
seed = 2
np.random.seed(seed)
[4]:
parameters = {
"a": 0.1,
"b": 0.05,
"dt": 0.01,
"t_start": 0,
"method": "rk4",
"t_end": 100.0,
"t_cut": 20,
"output": "output",
"initial_state": [0.5, 1.0],
}
[5]:
ode = DO(parameters)
print(ode())
Damped Oscillator Model (Numba)
-------------------------------
a = 0.1
b = 0.05
dt = 0.01
t_start = 0.0
t_end = 100.0
t_cut = 20.0
method = rk4
output = output
initial_state = [0.5 1. ]
<numba.experimental.jitclass.boxing.Param object at 0x7f55e80d5d20>
[6]:
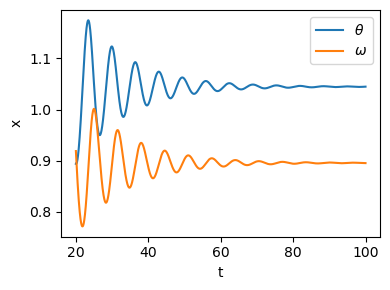
sol = ode.run()
t = sol["t"]
x = sol["x"]
plt.figure(figsize=(4, 3))
plt.plot(t, x[:, 0], label="$\\theta$")
plt.plot(t, x[:, 1], label="$\omega$")
plt.xlabel("t")
plt.ylabel("x")
plt.legend()
plt.tight_layout()
[7]:
cfg = get_features_by_domain(domain="statistical")
cfg = get_features_by_given_names(cfg, names=["calc_std", "calc_mean"])
report_cfg(cfg)
Selected features:
------------------
■ Domain: statistical
▢ Function: calc_std
▫ description: Computes the standard deviation of the signal.
▫ function : vbi.feature_extraction.features.calc_std
▫ parameters : {'indices': None, 'verbose': False}
▫ tag : all
▫ use : yes
▢ Function: calc_mean
▫ description: Computes the mean of the signal.
▫ function : vbi.feature_extraction.features.calc_mean
▫ parameters : {'indices': None, 'verbose': False}
▫ tag : all
▫ use : yes
[8]:
def wrapper(par, control, cfg, verbose=False):
ode = DO(par)
sol = ode.run(control)
# extract features
fs = 1.0 / par["dt"] * 1000 # [Hz]
stat_vec = extract_features(
ts=[sol["x"].T], cfg=cfg, fs=fs, n_workers=1, verbose=verbose
).values
return stat_vec[0]
[9]:
def batch_run(par, control_list, cfg, n_workers=1):
stat_vec = []
with Pool(processes=n_workers) as pool:
stat_vec = pool.starmap(
wrapper, [(par, control, cfg) for control in control_list]
)
return stat_vec
[10]:
control = {"a": 0.11, "b": 0.06}
x_ = wrapper(parameters, control, cfg)
print(x_)
[0.02651486 0.02314122 1.0525634 0.88261193]
[11]:
num_sim = 2000
num_workers = 10
a_min, a_max = 0.0, 1.0
b_min, b_max = 0.0, 1.0
prior_min = [a_min, b_min]
prior_max = [a_max, b_max]
prior = BoxUniform(low=prior_min, high=prior_max, seed=seed)
[12]:
theta = prior.sample(num_sim)
control_list = [{"a": theta[i, 0], "b": theta[i, 1]} for i in range(num_sim)]
[13]:
stat_vec = batch_run(parameters, control_list, cfg, n_workers=4)
[14]:
scaler = StandardScaler()
stat_vec = scaler.fit_transform(np.array(stat_vec))
[15]:
# stat_vec = np.array(stat_vec)
theta.shape, stat_vec.shape
[15]:
((2000, 2), (2000, 4))
[31]:
# --- observe data ---
theta_true = {"a": 0.1, "b": 0.1}
theta_true_np = np.array([theta_true["a"], theta_true["b"]])
xo = wrapper(parameters, theta_true, cfg)
xo = scaler.transform(xo.reshape(1, -1))
# --- train MDN ---
mdn_estimator = MDNEstimator(n_components=5, hidden_sizes=(32,32))
mdn_estimator.train(theta, stat_vec, n_iter=500, learning_rate=5e-4)
# --- sample from posterior ---
rng = anp.random.RandomState(seed)
samples = mdn_estimator.sample(xo, n_samples=5000, rng=rng)[0]
shrinkage = posterior_shrinkage_numpy(theta, samples)
zscore = posterior_zscore_numpy(theta_true_np, samples)
mdn_mean = np.mean(samples, axis=0)
Inferred dimensions: param_dim=2, feature_dim=4
/home/ziaee/anaconda3/envs/vbidevelop/lib/python3.10/site-packages/autograd/numpy/numpy_vjps.py:175: RuntimeWarning: overflow encountered in square
defvjp(anp.tanh, lambda ans, x: lambda g: g / anp.cosh(x) ** 2)
[17]:
print("True parameters: ", theta_true_np)
print("MDN mean estimate: ", mdn_mean)
print("Posterior shrinkage: ", np.array2string(shrinkage, precision=3, separator=", "))
print("Posterior z-score: ", np.array2string(zscore, precision=3, separator=", "))
True parameters: [0.1 0.1]
MDN mean estimate: [-0.08247562 0.08213305]
Posterior shrinkage: [-3582.025, -8.28 ]
Posterior z-score: [0.011, 0.02 ]
[ ]:
with open("output/posterior.pkl", "wb") as f:
pickle.dump(mdn_estimator, f)
# with open("output/posterior.pkl", "rb") as f:
# mdn_estimator = pickle.load(f)
[38]:
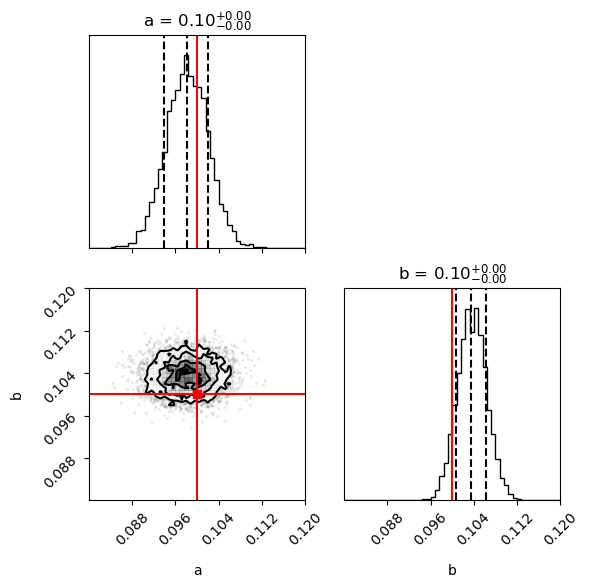
print("Plotting posterior marginals for MDN ...")
param_labels = ["a", "b"]
fig = corner.corner(
samples,
labels=param_labels,
truths=theta_true_np,
quantiles=[0.16, 0.5, 0.84],
show_titles=True,
title_kwargs={"fontsize": 12},
truth_color="red",
bins=50, # Increase number of bins for better resolution
range=[(0.08, 0.12), (0.08, 0.12)], # Adjust ranges
fig=plt.figure(figsize=(6, 6)),
)
plt.tight_layout()
plt.show()
Plotting posterior marginals for MDN ...
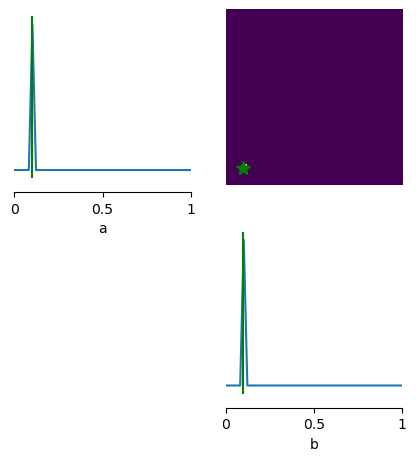
[36]:
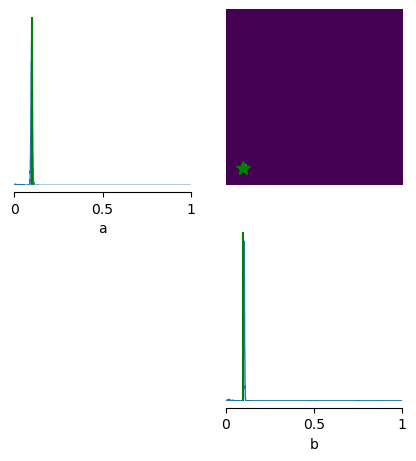
from vbi.plot import pairplot_numpy
limits = [(0.0, 1.0), (0.0, 1.0)]
fig, ax = pairplot_numpy(
samples,
points=theta_true_np.reshape(1, -1),
figsize=(5, 5),
limits=limits,
labels=["a", "b"],
# upper="kde",
# diag="kde",
fig_kwargs=dict(
points_offdiag=dict(marker="*", markersize=10),
points_colors=["g"],
),
)
[39]:
maf_estimator = MAFEstimator(n_flows=8, hidden_units=128)
maf_estimator.train(theta, stat_vec, n_iter=500, learning_rate=5e-4)
print("best epoch:", maf_estimator.best_epoch, "best val:", maf_estimator.best_val_loss)
samples = maf_estimator.sample(xo, n_samples=5000, rng=rng)[0]
shrinkage = posterior_shrinkage_numpy(theta, samples)
zscore = posterior_zscore_numpy(theta_true_np, samples)
print("True parameters: ", theta_true_np)
print("MDN mean estimate: ", np.mean(samples, axis=0))
print("Posterior shrinkage: ", np.array2string(shrinkage, precision=3, separator=", "))
print("Posterior z-score: ", np.array2string(zscore, precision=3, separator=", "))
Inferred dimensions: param_dim=2, feature_dim=4
Training: 0%| | 0/500 [00:00<?, ?it/s]Training: 82%|████████▏ | 412/500 [00:53<00:11, 7.64it/s, patience=20/20, train=-5.3812, val=-5.4610]
best epoch: 392 best val: -5.65872049331665
True parameters: [0.1 0.1]
MDN mean estimate: [0.10151861 0.10258637]
Posterior shrinkage: [1., 1.]
Posterior z-score: [0.311, 0.673]
[40]:
samples = maf_estimator.sample(xo, n_samples=5000, rng=rng)[0]
samples.shape
[40]:
(5000, 2)
[41]:
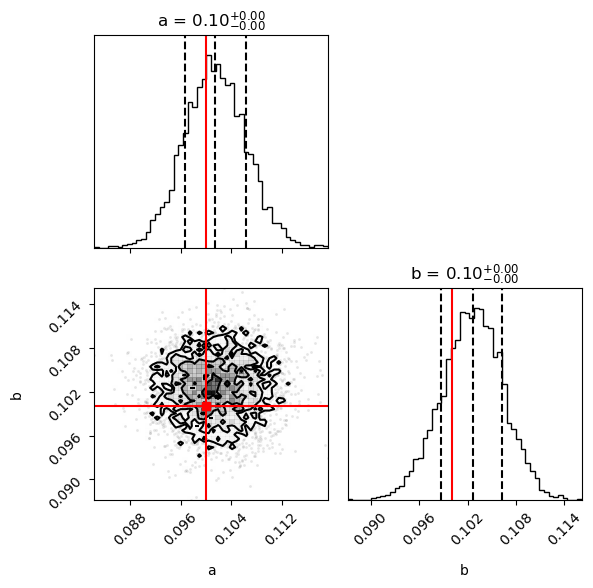
print("Plotting posterior marginals for MAF ...")
param_labels = ["a", "b"]
fig = corner.corner(
samples,
labels=param_labels,
truths=theta_true_np,
quantiles=[0.16, 0.5, 0.84],
show_titles=True,
title_kwargs={"fontsize": 12},
truth_color="red",
bins=50,
fig=plt.figure(figsize=(6, 6)),
)
plt.tight_layout()
plt.show()
Plotting posterior marginals for MAF ...
[42]:
from vbi.plot import pairplot_numpy
limits = [(0.0, 1.0), (0.0, 1.0)]
fig, ax = pairplot_numpy(
samples,
points=theta_true_np.reshape(1, -1),
figsize=(5, 5),
limits=limits,
labels=["a", "b"],
upper="kde",
diag="kde",
fig_kwargs=dict(
points_offdiag=dict(marker="*", markersize=10),
points_colors=["g"],
),
)
[ ]: